Abstract
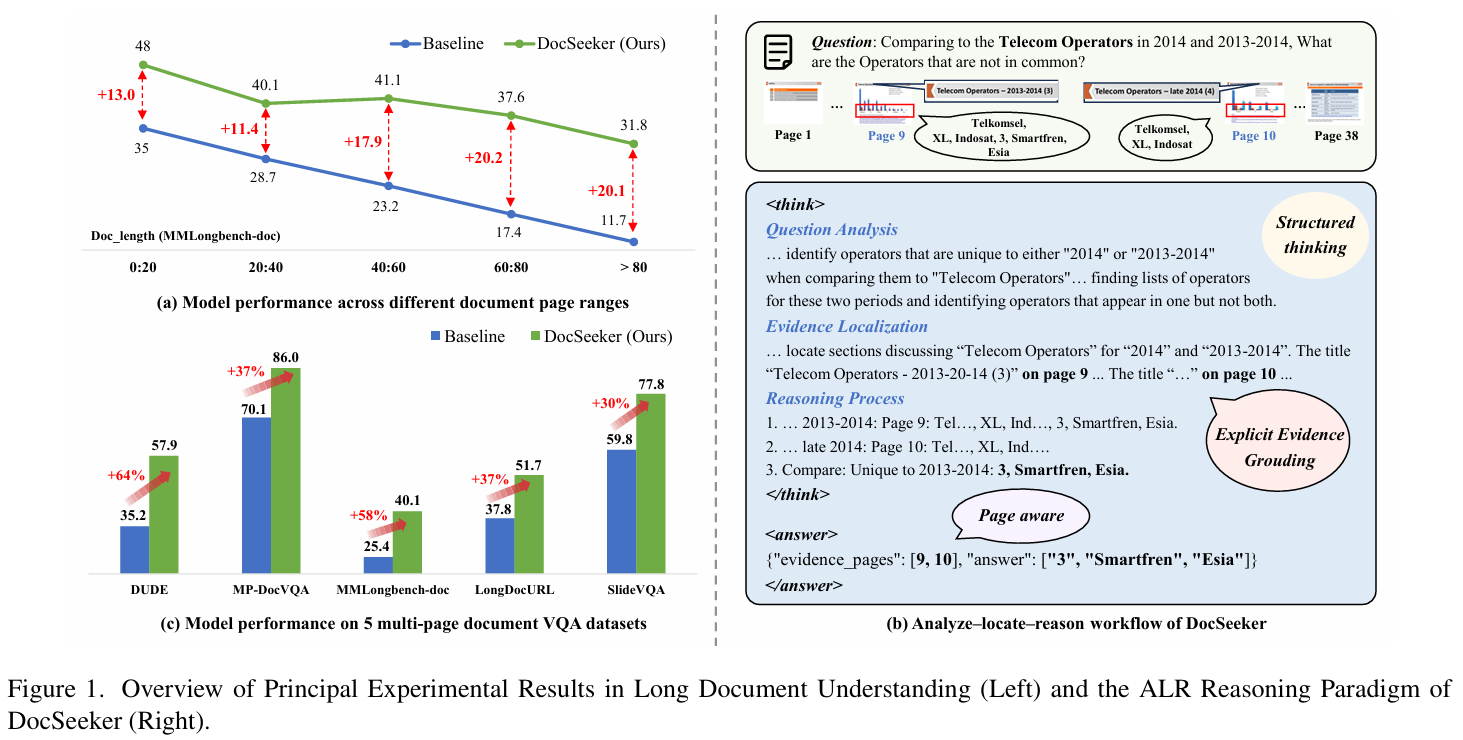
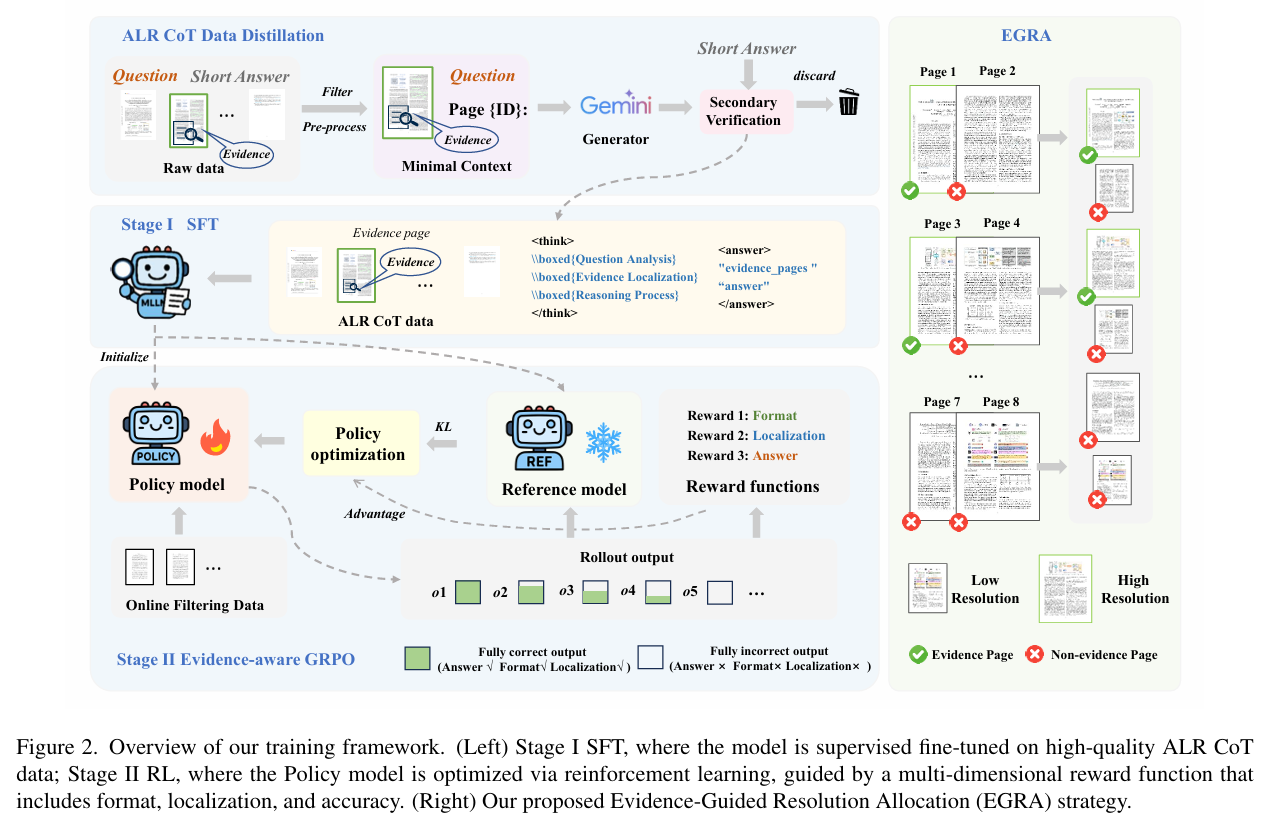
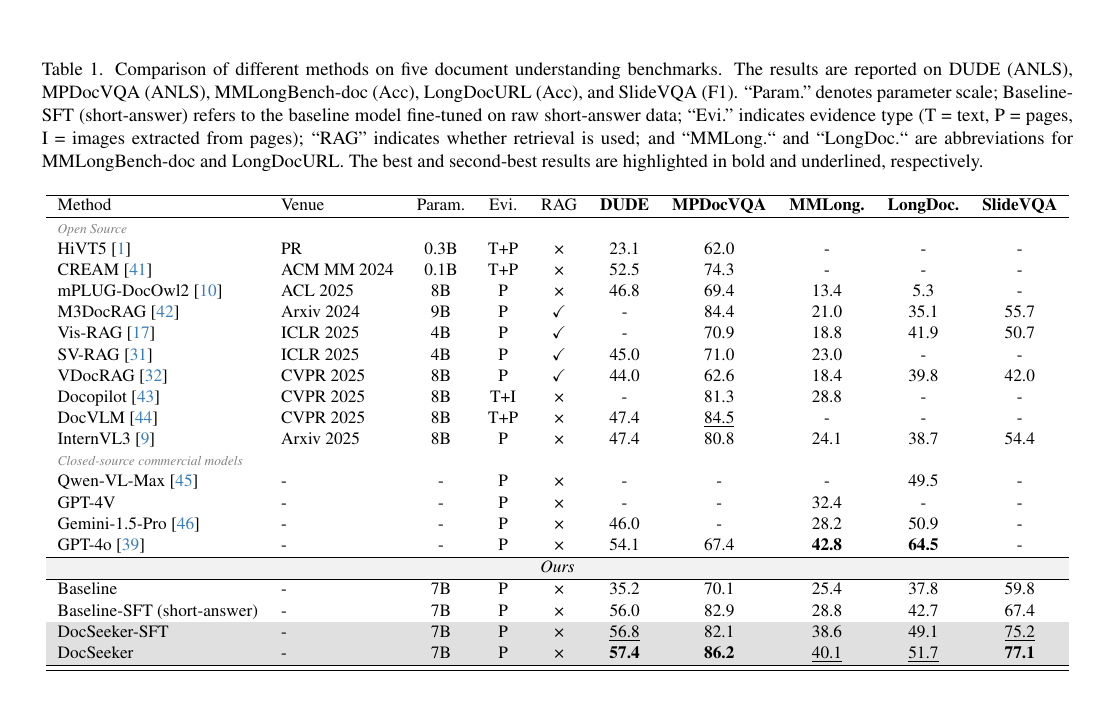
Existing Multimodal Large Language Models (MLLMs) suffer from significant performance degradation on the long document understanding task as document length increases. This stems from two fundamental challenges: (1) a low Signal-to-Noise Ratio (SNR), where crucial evidence is easily buried among irrelevant pages, and (2) supervision scarcity, since datasets that provide only final short answers offer a weak learning signal. In this paper, we address these challenges by introducing a paradigm that requires the model to execute a structured Analysis–Localization–Reasoning workflow. To instill this capability, we design a two-stage training framework. We first perform supervised fine-tuning on high-quality data generated through an efficient knowledge distillation strategy. We then employ Evidence-aware Group Relative Policy Optimization to jointly optimize evidence localization and answer accuracy. In addition, we introduce an Evidence-Guided Resolution Allocation strategy to mitigate the memory constraints of training on multi-page documents. Extensive experiments show that DocSeeker achieves superior performance on both in-domain and out-of-domain benchmarks. The model generalizes robustly from short-page training to ultra-long documents and works naturally with visual Retrieval-Augmented Generation systems, providing a strong foundation for building practical long-document reasoning pipelines.